Abstract
Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self- supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training performs on par or better than fully supervised baselines while not requiring 3D annotations on real data.
Method
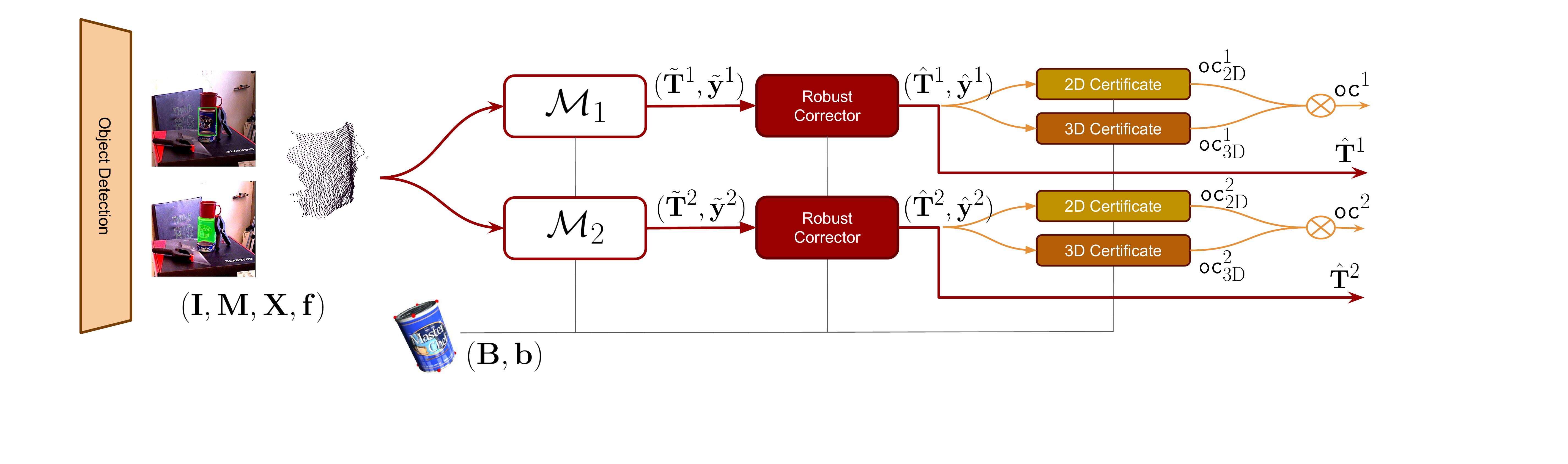
The proposed architecture (see the diagram above) stacks several pose estimation models in parallel. The two models output object pose estimates and keypoints. Two binary certificates, namely, the 2D and 3D certificates check geometric consistency of the corrected pose. If the 2D and 3D checks succeed, the corrected pose is declared to be observably correct. The architecture outputs an observably correct pose, and if none is found, it outputs the corrected pose of a preferred model.
Results Hightlights
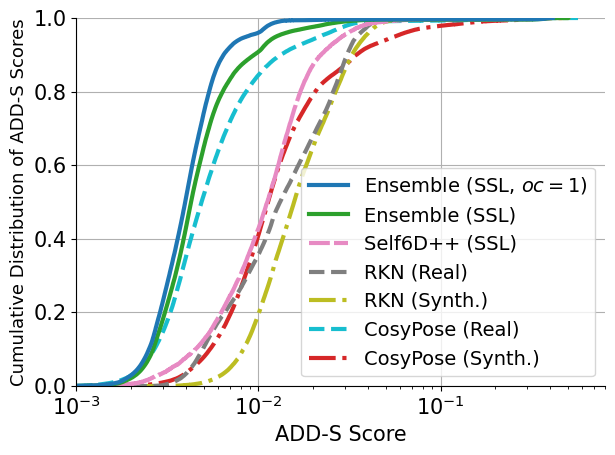
In the left plot, we show the cumulative distribution of ADD-S scores, averaged across all objects in the YCBV dataset, for the proposed ensemble self-training architecture (Ensemble) and other baselines. The figure shows that the proposed ensemble self-training outperforms by a small margin the fully supervised RKN (Real) and CosyPose (Real) approaches on the YCBV test dataset. The figure also shows the performance of only the observably correct outputs produced by Ensemble, i.e., Ensemble (SSL, oc = 1). We see that these exhibit a further performance boost, indicating that our certificates of observable correctness are indeed able to identify correct outputs. We also observe that the proposed ensemble self-training significantly outperforms Self6D++ — a state-of-the-art, self-supervised pose estimation method.
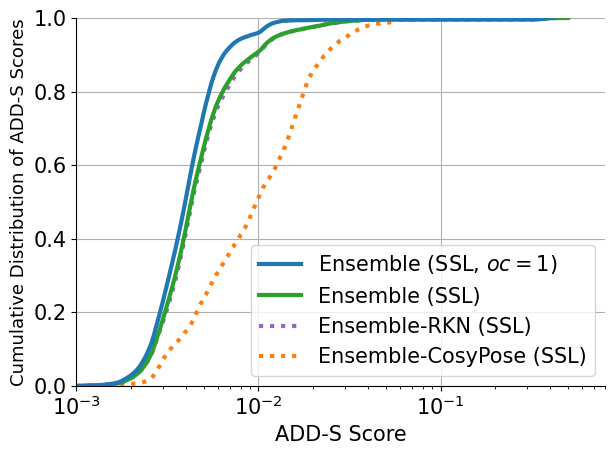
In the right plot, we show the cumulative distribution of ADD-S scores, across all objects in the YCBV dataset, for Ensemble and its branches. We observe that Ensemble-RKN contributes the most. This is partly because RKN, in the RKN-branch, works directly on the RGB-D input, as opposed to CosyPose, which only relies on RGB information. However, a significant performance boost to RKN is provided by the robust corrector.
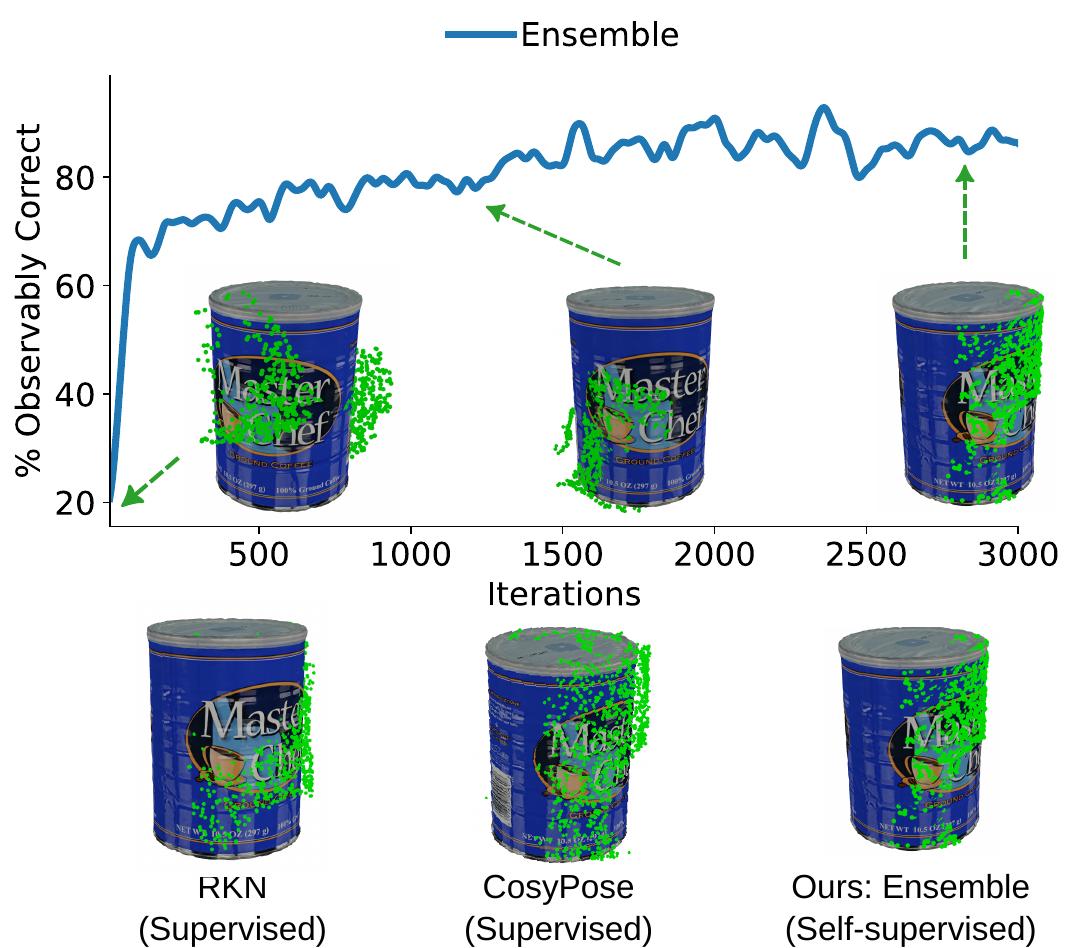
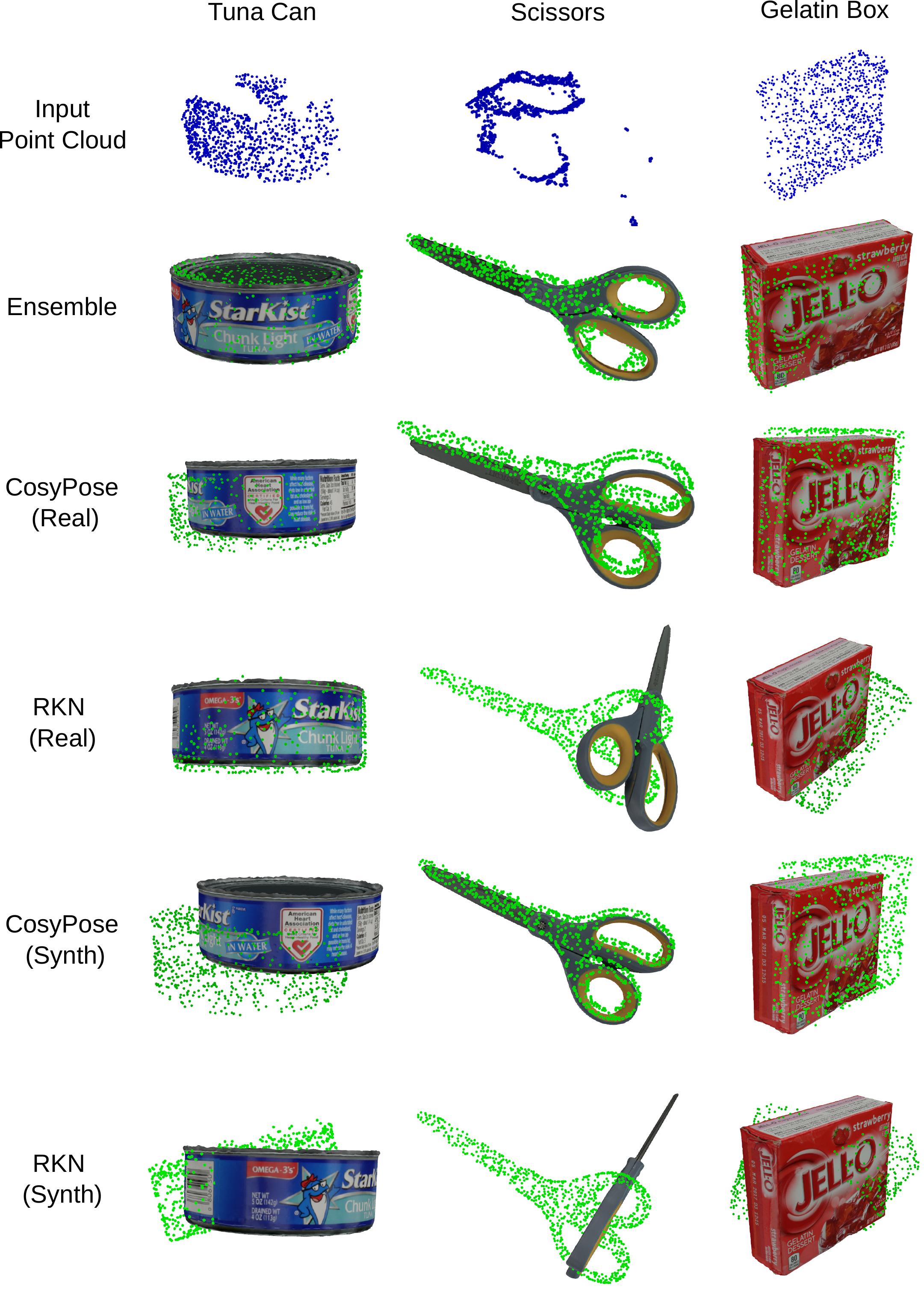
Qualitative Examples
BibTeX Citation
@inproceedings{Shi23rss-ensemble,
title = {A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training},
author = {Jingnan Shi, Rajat Talak, Dominic Maggio and Luca Carlone},
booktitle={Robotics: Science and Systems (RSS)},
year={2023}
}